Viewing posts for the category Featured on frontpage
Visualizing the bivariate Gaussian distribution
Posted by: christian in Featured on frontpage on 3 Aug 2016
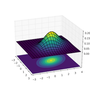
The multivariate Gaussian distribution of an $n$-dimensional vector $\boldsymbol{x}=(x_1, x_2, \cdots, x_n)$ may be written
Visualizing the gradient descent method
Posted by: christian in Featured on frontpage on 5 Jun 2016

In the gradient descent method of optimization, a hypothesis function, $h_\boldsymbol{\theta}(x)$, is fitted to a data set, $(x^{(i)}, y^{(i)})$ ($i=1,2,\cdots,m$) by minimizing an associated cost function, $J(\boldsymbol{\theta})$ in terms of the parameters $\boldsymbol\theta = \theta_0, \theta_1, \cdots$. The cost function describes how closely the hypothesis fits the data for a given choice of $\boldsymbol \theta$.