Posted by: christian on 22 Apr 2016
The Daily Telegraph publishes an announcements page online. The death announcements category consists of a series of short paragraphs placed by readers communicating the recent death of a relative. The fact that these relatives often expire either "peacefully" or "suddenly" (and sometimes both) is the basis of the peacefully/suddenly game: a popular pastime for long train journeys in the United Kingdom.
But what proportion of Telegraph readers die peacefully as opposed to suddenly? Python can help.
To analyse the data we first need to obtain the obituary notices. The Telegraph is not obliging enough to provide an API to access this part of its website, but the pages are generated from some database backend and have a predictable structure which helps in scraping them.
First the index pages: these list 10 announcements at a time, the most recent at http://announcements.telegraph.co.uk/deaths/announcements/1, with subsequent pages (older announcements) at pages accessed by increasing the last number in this URL. The index pages themselves do not provide the full announcement, but contain links to individual announcement pages: it is these link URLs that we need. There's a small complication that each abbreviated announcement contains various links to different parts of the same page (through # anchors): we generate a set of links which do not have this anchor in their URL.
The following code does this, using Python 3's urllib to obtain the HTML and BeautifulSoup to parse it.
import re
import urllib
from bs4 import BeautifulSoup
def get_links_from_page(n, links):
"""Get all obituary links from the page .../deaths/announcements/n.
There seem to be a maximum of 10 obituaries per page; each page is
identified by a counting number, n. The set links is updated with the
URL of each obituary link encountered on this page.
"""
request = urllib.request.Request('http://announcements.telegraph.co.uk'
'/deaths/announcements/{:d}'.format(n))
result = urllib.request.urlopen(request)
resulttext = result.read()
soup = BeautifulSoup(resulttext,'html.parser')
# We seek URLs matching the following regex
patt = 'http:\/\/announcements.telegraph.co.uk\/deaths\/\d+\/[^#]+$'
for anchor in soup.find_all('a'):
link = anchor.get('href', '/')
if re.match(patt, link):
links.add(link)
# Get the first 1000 obituary URLs.
links = set()
n = 0
while len(links) < 1000:
n += 1
print(n)
get_links_from_page(n, links)
# Save the URLs to a text file.
with open('ps-links.txt', 'w') as fo:
for link in links:
print(link, file=fo)
Now we have the URLs for the announcements' webpages, we want to scrape the actual announcement text itself from each HTML file. Again, we can use urllib and BeautifulSoup. The text lives within a p tag within a div with the class detail-ad-text (the Telegraph apparently regards death announcements as advertisements). We write the announcements (one per line) to a text file for subsequent analysis.
import urllib
from bs4 import BeautifulSoup
def get_obit_from_link(link):
"""Extract the death announcement text from the URL at link."""
request = urllib.request.Request(link)
result = urllib.request.urlopen(request)
resulttext = result.read()
soup = BeautifulSoup(resulttext,'html.parser')
# Get the div with the class "detail-ad-text". Make sure there's only one.
divs = soup.findAll("div", { "class" : "detail-ad-text" })
if len(divs) != 1:
print('Skipping link {}: number of matching divs found is {}'
.format(link, len(divs)))
return ''
# Extract and return the announcement text from the <p> inside this div.
text = divs[0].p.string
return text
# Read in the death announcement URL list.
with open('ps-links.txt') as fi:
links = fi.readlines()
# For each announcement URL, extract the announcement text and write to a file.
with open('obits.txt', 'a') as fo:
for i, link in enumerate(links):
link = link.strip()
print(i+1, link)
obit_text = get_obit_from_link(link)
print(obit_text, file=fo)
Now we're ready to examine the announcements. This is simple using Python's string processing methods. We count "suddenly" and "unexpectedly" as the same, even though I suppose they aren't, quite.
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Circle
# Read in the obituaries (one per line)
with open('obits.txt') as fi:
obits = fi.readlines()
# Count the number of obituaries containing the word "peacefully", the
# words "suddenly" or "unexpectedly", and those containing both.
total = len(obits)
peacefully_count = 0
suddenly_count = 0
both_count = 0
for obit in obits:
obit = obit.lower()
peacefully = 'peacefully' in obit
suddenly = 'suddenly' in obit or 'unexpectedly' in obit
peacefully_count += peacefully
suddenly_count += suddenly
both_count += peacefully and suddenly
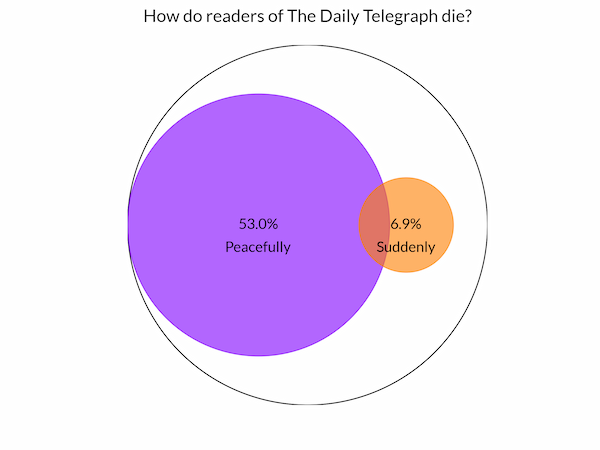
print('Peacefully: {}/{}'.format(peacefully_count, total))
print('Suddenly: {}/{}'.format(suddenly_count, total))
print('Both: {}/{}'.format(both_count, total))
# The area of the circles is proportional to the fraction of obituaries in
# each group; their radii are proportional to the square root of their areas.
Ap = peacefully_count/total
As = suddenly_count/total
Ab = both_count/total
# The radius
rp = np.sqrt(Ap)
rs = np.sqrt(As)
rb = np.sqrt(Ab)
# Plot our circles inside a circle or radius 1, representing all obituaries.
fig, ax = plt.subplots(facecolor='w')
ax.set_aspect('equal')
ax.set_xlim(-1,1)
ax.set_ylim(-1,1)
c_all = Circle((0,0), 1, fc='w')
PURPLE = (0.5,0,1,0.6)
ORANGE = (1,0.5,0,0.6)
# The (x, y) centres of the "peacefully" and "suddenly" circles.
cp = (-(1-rp), 0)
cs = (-(1-rp)+0.82,0) # NB hard-code the overlap because it's hard to calculate
c_peacefully = Circle(cp, rp, fc=PURPLE, ec=PURPLE)
c_suddenly = Circle(cs, rs, fc=ORANGE, ec=ORANGE)
for patch in (c_all, c_peacefully, c_suddenly):
ax.add_artist(patch)
# Annotate with the percentages for each group
cperc = peacefully_count / total * 100
sperc = suddenly_count / total * 100
ax.annotate(s='{:.1f}%'.format(cperc), xy=cp, ha='center', va='center')
ax.annotate(s='Peacefully', xy=(cp[0], -0.15), color='k', ha='center')
ax.annotate(s='{:.1f}%'.format(sperc), xy=cs, ha='center', va='center')
ax.annotate(s='Suddenly', xy=(cs[0], -0.15), color='k', ha='center')
# Displace the title upwards a bit so it's not too close to the big circle.
ax.set_title('How do readers of The Daily Telegraph die?', y=1.05)
plt.axis('off')
plt.show()
Note that in the context of a lines such as
peacefully = 'peacefully' in obit
peacefully_count += peacefully
the boolean object peacefully is interpreted as an integer (1 for True and 0 for False) for the addition to the counter peacefully_count.
Comments
Comments are pre-moderated. Please be patient and your comment will appear soon.
Julia 8 years, 3 months ago
I'm glad it's not just my family that plays the peacefully-suddenly game!
Link | ReplyNew Comment