Learning Scientific Programming with Python (2nd edition)
E7.9: Letter frequencies in Moby Dick
The following program produces a bar chart of letter frequencies in the English language, estimated by analysis of the text of Moby Dick (available as a free download from Project Gutenberg). The vertical bars are centered, and labelled by letter.
import numpy as np
import matplotlib.pyplot as plt
text_file = "moby-dick.txt"
letters = "ABCDEFGHIJKLMNOPQRSTUVWXYZ"
# Initialize the dictionary of letter counts: {'A': 0, 'B': 0, ...}
lcount = dict([(l, 0) for l in letters])
# Read in the text and count the letter occurences
for l in open(text_file).read():
try:
lcount[l.upper()] += 1
except KeyError:
# Ignore characters that are not letters
pass
# The total number of letters
norm = sum(lcount.values())
fig = plt.figure()
ax = fig.add_subplot(111)
# The bar chart, with letters along the horizontal axis and the calculated
# letter frequencies as percentages as the bar height
x = range(26)
ax.bar(
x,
[lcount[l] / norm * 100 for l in letters],
width=0.8,
color="g",
alpha=0.5,
align="center",
)
ax.set_xticks(x)
ax.set_xticklabels(letters)
ax.tick_params(axis="x", direction="out")
ax.set_xlim(-0.5, 25.5)
ax.yaxis.grid(True, ls=":", lw=0.5)
ax.set_ylabel("Letter frequency, %")
plt.show()Note: if you get a UnicodeDecodeError when running the above code, you might be using Windows. It will probably help to explicitly declare the encoding of the Moby Dick text file by replacing the relevant line above with
for l in open(text_file, encoding='utf8').read():
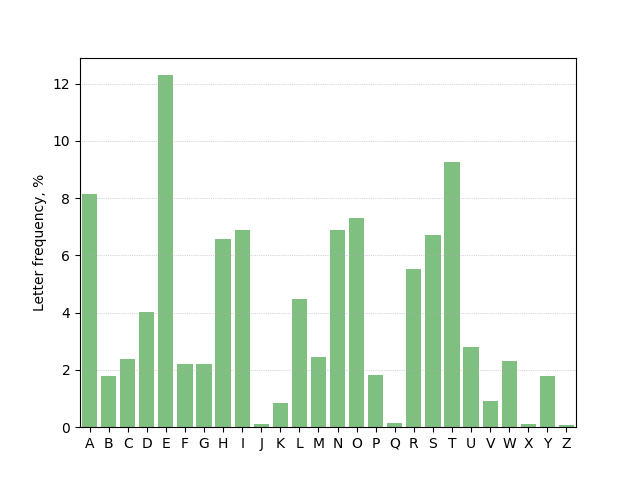
Letter frequencies in Moby Dick.