Impact craters on Earth
Posted on 28 July 2019
The Earth Impact Database is a collection of images, publications and abstracts that provides information about confirmed impact structures for the scientific community. It is hosted at the Planetary and Space Science Centre (PASSC) of the University of New Brunswick.
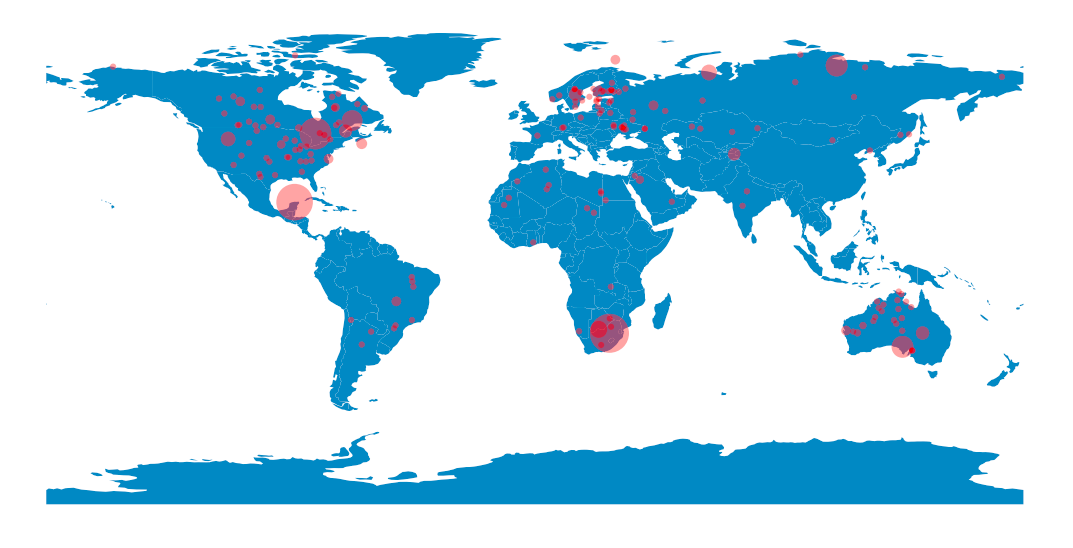
Oldest crater: Suavjärvi (63.1, 33.4), 16.0 km, 2400.0 Ma
--
Largest impact crater in North America:
Chicxulub (21.3, -88.5), 150.0 km, 64.98 Ma
--
Largest impact crater in South America:
Araguainha (-15.2, -51.0), 40.0 km, 254.7 Ma
--
Largest impact crater in Europe:
Siljan (61.0, 14.9), 52.0 km, 376.8 Ma
--
Largest impact crater in Asia:
Popigai (71.7, 111.2), 90.0 km, 35.7 Ma
--
Largest impact crater in Africa:
Vredefort (-27.0, 27.5), 160.0 km, 2023.0 Ma
--
Largest impact crater in Australia:
Acraman (-32.0, 135.4), 90.0 km, 590.0 Ma
The code is also presented in a Jupyter Notebook on this github repository.
import os
import urllib.request
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import geopandas
# The directory we're going to save local copies of the HTML files into.
HTML_DIR = 'html'
if not os.path.exists(HTML_DIR):
os.mkdir(HTML_DIR)
# The URLs for the HTML files at the online Earth Impact Database (EID).
BASE_URL = 'http://www.passc.net/EarthImpactDatabase/New%20website_05-2018/'
urls = {'North America': BASE_URL + 'NorthAmerica.html',
'South America': BASE_URL + 'SouthAmerica.html',
'Europe': BASE_URL + 'Europe.html',
'Asia': BASE_URL + 'AsiaRussia.html',
'Africa': BASE_URL + 'Africa.html',
'Australia': BASE_URL + 'Australia.html'
}
# Make a dictionary of local filenames (without path). Use the same filename as
# on the EID server.
filenames = dict((continent,
url.rsplit('/', 1)[-1]) for continent ,url in urls.items())
def get_htmlpath(filename):
"""Get qualified path to local HTML file filename."""
return os.path.join(HTML_DIR, filename)
def fetch_html(continent, filename):
"""Fetch HTML file for continent from internet and save as filename."""
print('Fetching HTML file', filename)
url = urls[continent]
req = urllib.request.urlopen(url)
html = req.read().decode()
with open(get_htmlpath(filename), 'w') as fo:
fo.write(html)
# Fetch the HTML into local files if we don't have them already.
for continent, filename in filenames.items():
if not os.path.exists(get_htmlpath(filename)):
fetch_html(continent, filename)
def parse_latlong(s):
"""Parse an angle in degrees and minutes into a decimal float."""
s = s.replace('N','').replace('S','-').replace('W','-').replace('E','')
s = s.replace(' ','').replace("'",'')
d, m = s.split('°')
return float(d) + float(m)/60
def parse_numeric(s):
"""Parse s into a float if possible, ignoring asterisks."""
s = s.replace('*', '')
return pd.to_numeric(s, errors='coerce')
def parse_age(s):
"""Parse s into a crater age if possible, handling uncertainties."""
note = ''
s = s.replace('*', '')
if '<' in s:
note = 'upper bound'
elif '>' in s:
note = 'lower bound'
elif '~' in s:
note = 'approximate age'
s = s.replace('<', '').replace('>', '').replace('~', '')
if '±' in s:
age, unc = s.split('±')
return float(age), float(unc), note
elif '-' in s:
lower_age, upper_age = s.split('-')
try:
lower_age, upper_age = float(lower_age), float(upper_age)
except ValueError:
return np.nan, np.nan, 'parsing age failed'
mean_age = (lower_age + upper_age) / 2
unc = mean_age - lower_age
return mean_age, unc, note
try:
return float(s), np.nan, note
except ValueError:
return np.nan, np.nan, 'parsing age failed'
def read_html_to_pd(filename):
filepath = get_htmlpath(filename)
# It's the second table we want.
df = pd.read_html(filepath)[1]
# The column names have been put in the first row: fix this.
df.columns = df.iloc[0]
df = df.reindex(df.index.drop(0))
# Convert longitude and latitude strings to floats
df['Longitude'] = df['Longitude'].apply(parse_latlong)
df['Latitude'] = df['Latitude'].apply(parse_latlong)
df['Diameter (km)'] = df['Diameter (km)'].apply(parse_numeric)
df['Age (Ma)*'], df['Age unc. (Ma)'], df['Note'] = zip(
*df['Age (Ma)*'].apply(parse_age))
df['Exposed'] = df['Exposed'] == 'Y'
df['Drilled'] = df['Drilled'] == 'Y'
return df
dd = {}
# Parse the HTML tables for the data, for each continent
for continent, filename in filenames.items():
dd[continent] = read_html_to_pd(filename)
df = pd.concat(dd)
def crater_summary(crater):
"""Return a string summarizing the important features of crater."""
return (f"{crater['Crater Name']} "
f"({crater['Latitude']:.1f}, {crater['Longitude']:.1f})"
f", {crater['Diameter (km)']} km, {crater['Age (Ma)*']} Ma")
i_oldest = df['Age (Ma)*'].idxmax()
print('Oldest crater:', crater_summary(df.loc[i_oldest]))
for continent in filenames.keys():
i_largest = df.loc[continent].loc[:,'Diameter (km)'].idxmax()
print('--')
print('Largest impact crater in {}:'.format(continent))
print(crater_summary(df.loc[continent].loc[i_largest]))
fig, ax = plt.subplots()
ax.set_aspect('equal')
world = geopandas.read_file(geopandas.datasets.get_path('naturalearth_lowres'))
world.plot(ax=ax)
sizes = np.clip((np.pi*df['Diameter (km)']/2)**2 / 80, 20, None)
ax.scatter(df['Longitude'], df['Latitude'], c='r', alpha=0.4, s=sizes,
edgecolor='none')
ax.axis('off')
plt.show()